Cours 2 : concepts élémentaires en sondage
13 févr. 2026
Objectifs du cours :
- Comprendre les notions de population, d’échantillon et plan de sondage.
- Se remémorer quelques éléments de statistique inférentielle.
- Manipuler l’estimateur de Narain-Horvitz-Thompson.
Population, échantillon, variables et plan de sondage
Population
- La population correspond aux individus sur lesquels on souhaite obtenir de l’information.
- Exemple de population :
- l’ensemble des étudiants de l’université de Paris 1
- \(\mathcal{U}_\text{Paris 1} = \{1, ..., 45\ 200\}\) : Identification possible avec le INE.
- l’ensemble des logements en France
- \(\mathcal{U}_\text{log} = \{1, ..., 29\ 000\ 000 \}\) : Identification (presque) possible avec le cadastre.
- l’ensemble des communes de France
- \(\mathcal{U}_\text{communes} = \{1, ..., 36\ 500 \}\) : Identification (presque) possible avec le COG.
- l’ensemble des étudiants de l’université de Paris 1
- Autres exemples :
Population
- Plus formellement, une population de taille \(N\) correspond à un ensemble de \(N\) individus identifiables \(\to\) la population sera décrite par une variable identifiante.
- Définition : population
- Une population d’individus \(\mathcal{U}\) de taille \(N\) sera décrite formellement par l’ensemble \(\{1, 2, ..., N\}\) où chaque élément \(k \in [\![ 1 , N ]\!]\) désigne un individu.
Population

Exemple de population
Échantillon
- But : obtenir de l’information sur \(\mathcal{U}\).
- Exemple d’informations
- Estimation de la distribution des activités exercées par les entreprises.
- Estimation du taux de chômage.
- Estimation de la consommation de boissons alcoolisées des étudiants.
- Estimation de la proportion de passoires énergétiques
Comment ?
En utilisant un sous-ensemble de \(\mathcal{U}\) et en utilisant des résultats de théorie des sondages : il s’agit de l’échantillon.
L’échantillon peut être appréhendé comme un sous-ensemble de la population.
Définition 1 (Echantillon) Un échantillon \(s\) de taille \(n\) d’une population \(\mathcal{U}\) de taille \(N\) est un sous-ensemble de \(\mathcal{U}\) de taille \(n\).
Dans ce cours, les échantillons sont donc tirés sans remise (et sans prise en compte de l’ordre).
Échantillon

- Population \(\mathcal{U} = \{1,2,3,4,5,6,7,8,9, 10\}\).
- Échantillon \(s = \{1,5,7,10\}\).
Variables d’intérêt, variables auxiliaires et fonction d’intérêt.
À partir de notre population et de notre échantillon, deux grandes familles de variables :
Définition 2 (Variables auxiliaires.) Les variables auxiliaires sont des variables disponibles pour les individus de l’échantillon \(s\) ou de la population \(\mathcal{U}\) connues avant la collecte.
Elles permettent :
- de définir le plan de sondage,
- de corriger la non-réponse,
- de caler.
Elles sont généralement notées \(\textbf{x} = (x_1, ..., x_p) \in \mathbb{R}^p\) et \(x_k\) désigne les valeurs des variables auxiliaires de l’individu \(k\).
- Exemples
- adresse
- informations fiscales
Présentation
| Identifiant | Prénom | Âge | Code postal | Profession |
|---|---|---|---|---|
| 1 | Hayem | 26 | 35170 | Ingénieure |
| 2 | Alice | 27 | 78000 | Prof. |
| 3 | Raymond | 78 | 59300 | Agriculteur |
| 4 | Manon | 48 | 02000 | Indépendante |
| 5 | Hugo | 27 | 92120 | Statisticien |
| 6 | Amira | 30 | 31000 | Tyran |
| 7 | Billel | 70 | 59000 | Retraite |
| 8 | Isaac | 10 | 59000 | Élève |
| 9 | Laurent | 52 | 97401 | Chef d’entreprise |
| 10 | Manu | 40 | 75000 | Chef |
Variables d’intérêt, variables auxiliaires et fonction d’intérêt.
À partir de notre population et de notre échantillon, deux grandes familles de variables :
Définition 3 (Variables d’intérêt) Les variables d’intérêt sont des variables dont les valeurs sont obtenues après collecte : bien que ces variables soient définies sur l’ensemble de la population \(\mathcal{U}\), elles ne sont observables que sur l’échantillon \(s\).
Elles sont généralement notées \(\textbf{y} = (y_1, ..., y_d) \in \mathbb{R}^d\) et \(\textbf{y}_k\) désigne la valeur de la valeur d’intérêt de l’individu \(k\).
Dans la suite, nous supposons que nous récupérons qu’une seule variable d’intérêt 1 \(\textbf{y} = y \in \mathbb{R}\).
On note : \(\{y_k\}_{k \in \mathcal{U}}\) les valeurs de la variable d’intérêt sur l’ensemble de la population et \(\{y_k\}_{k \in s}\) sur l’échantillon.
- Exemples
- Enquête Histoire de Vie et Patrimoine : valeurs du patrimoine.
- Enquête Emploi en continu : indicatrice d’activité.
Illustration
| Identifiant | Nb de semaines de vacances en 2025 |
|---|---|
| 1 | 1 |
| 5 | 0 |
| 7 | 3 |
| 10 | 15 |
La variable Nb de semaines de vacances en 2025 existe également pour les individus non tirés mais nous ne connaissons pas sa valeur.
Variables d’intérêt, variables auxiliaires et fonction d’intérêt.
Généralement, le statisticien souhaite de l’information des variables d’intérêt sur l’ensemble de la population. Par exemple : le nombre moyen de semaines de vacances sur la population \(\mathcal{U} = \{1,...,10 \}\). Il souhaiterait donc pouvoir calculer certaines fonctions des variables d’intérêt \(\{\textbf{y}_k\}_{k \in \mathcal{U}}\) \(\to\) fonctions d’intérêt.
Définition 4 (Fonction d’intérêt) Une fonction d’intérêt (ou paramètre d’intérêt) pour les variables d’intérêt \(\textbf{y}\) est une fonction \(\theta(\{y_k\}_{k \in \mathcal{U}})\) où \(\theta : \mathbb{R}^N \to \mathbb{R}^{d_\text{interêt}}\).
Ces statistiques ne peuvent être calculées même après collecte car nous ne disposons que de l’information sur \(s\).
- Exemples :
- la moyenne du nombre de congés.
- la médiane (ou autres quantiles) du nombre de congés.
- le total de congés.
Dans la définition, aucune hypothèse n’est imposée sur \(\theta\).
Cependant, nous verrons qu’en imposant des hypothèses de régularité sur cette fonction, il sera plus simple d’inférer (par exemple, utilisation de la linéralisation pour l’estimation de variance).
Dans ce cours : \(\theta\) sera soit le total soit une fonction régulière des totaux de variables d’intérêt.
Par exemple,
\(\displaystyle \theta_1(\{\textbf{y}_k \})_{k\in \mathcal{U}} = \frac{1}{N} \sum_{k \in \mathcal{U}} \textbf{y}_k\)
\(\displaystyle \theta_2(\{\textbf{y}_k \})_{k\in \mathcal{U}} = \max_{k \in \mathcal{U}} \{\textbf{y}_k \}\)
Plan de sondage
L’échantillon sera au coeur de l’inférence sur la population : l’aléa en sondage porte uniquement sur la manière dont on le tire \(\to\) formalisation à l’aide la notion de plan de sondage.
Idée du plan de sondage : attribuer à chaque échantillon possible une probabilité d’être tiré.
Exemple
- \(\mathbb{P}(S = \{1\}) = 0.0001\)
- \(\mathbb{P}(S = \{2\} ) = 0.0001\)
- \(\mathbb{P}(S = \{9\}) = 0.0002\)
- \(\mathbb{P}(S = \{10\}) = 0.0001\)
- \(\mathbb{P}(S = \{1,2\}) = 0.00015\)
- \(\mathbb{P}(S = \{1,3\} ) = 0.00027\)
- \(\mathbb{P}(S = \{2,3\}) = 0.0008\)
…
- \(\mathbb{P}(S = \{1,2,3,4,5,6,7,8,9\}) = 0.02\)
- \(\mathbb{P}(S = \{1,2,3,4,5,6,7,9,10\} ) = 0.001\)
- \(\mathbb{P}(S = \{1,2,3,4,5,6,8,9,10\}) = 0.005\)
- \(\mathbb{P}(S = \{1,2,3,4,5,7,8,9,10\}) = 0.0017\)
- \(\mathbb{P}(S = \{2,4\}) = 0.0002\)
- \(\mathbb{P}(S = \{2,5\}) = 0.00015\)
Pour rappel, dans notre exemple, on identifie chaque individu grâce à un identifiant qui est un nombre compris entre 1 et 10 (voir la table Population) :
- \(\mathbb{P}(S = \{2\} ) = 0.0001\) signifie que la probabilité que l’échantillon tiré aléatoirement ne contienne qu’Alice (individu dont l’identifiant est \(2\)) est de \(0.0001\).
- \(\mathbb{P}(S = \{2,5\}) = 0.00015\) signifie que la probabilité que l’échantillon tiré aléatoirement ne contienne qu’Alice et Hugo (individu dont l’identifiant est \(2\) et \(5\)) est de \(0.00015\).
Plan de sondage
Définition 5 (Plan de sondage) Un plan de sondage est une mesure de probabilité sur \((\mathcal{P}(\mathcal{U}), \mathcal{P}(\mathcal{P}(\mathcal{U}))).\)
Pour définir un plan de sondage, il faut donner la probabilité de \(2^N - 1\) probabilités évènements.
Si \(N > 266\), \(\to\) \(2^N > 10^{80} \approx\) nombre d’atomes dans l’univers observable.
En général, définition par algorithme ou basé sur des plans de sondage connus.
- Exemple de plan de sondage :
- Définition algorithmique :
- Tirage avec une probabilité de \(\frac{1}{2}\) (et de manière indépendante) des individus soumis à l’IFI.
- Tirage d’un échantillon de communes (avec certaines probabilités) puis au sein de ces communes, tirage de logements (avec certaines prob) puis tirages avec individus (avec certaines prob).
- Définition en détaillant les probabilités :
- Tirage des individus en faisant des piles ou faces de manière indépendante : \(\mathbb{P}(S = s) = (\prod_{k \in s} p_k)(\prod_{k \notin s} (1-p_k))\)
- Tirage d’un échantillon en affectant une probabilité non nulle uniquement aux échantillons contenant deux individus : pour tout \(s \subset \mathcal{U}\) tel que \(s\) est de taille 2 alors \(\mathbb{P}(S = s) = \frac{1}{\binom{N}{2}}\) où \(N\) est la taille de la population et si \(s\) est de taille diférrente de 2, \(\mathbb{P}(S = s) = 0\)
- Définition algorithmique :
Sondage aléatoire simple sans remise
Le sondage aléatoire simple sans remise (ou SASSR1) est un plan de sondage prenant comme paramètre un entier \(n\), la taille de l’échantillon souhaité.
\(S\) suit un plan aléatoire simple sans remise de paramètre \(n\) (SASSR(\(n\))) si :
- tous les sous-ensembles de taille \(n\) ont la même probabilité d’être tiré.
- tous les sous-ensembles de taille différent de \(n\) ont une probabilité nulle d’être tiré.
Plus formellement, pour tout sous-ensemble \(s\) de taille \(n\) de \(\mathcal{U}\), \(\mathbb{P}(S = s) = \frac{1}{\binom{N}{n}}\).
Ce plan est régulièrement utilisé comme élément de base pour des plans de sondage plus complexes
Sondage aléatoire simple sans remise
- Le plan aléatoire simple sans remise de taille \(n\) dans une population de taille \(N\) est donné par la fonction de masse, pour tout \(s\subset \mathcal{U}~~\), \(\mathbb{P}(S = s) = \frac{1}{\binom{N}{n}}\)
- Mais comment tirer un échantillon dans une population \(\mathcal{U}\) de taille \(N\) ?
- A partir de la fonction, possibilité d’utiliser le principe fondamemntal des simulations \(\to\) problème : trop d’échantillons possibles.
- Il faut donc trouver un algorithme efficace permettant de tirer selon ce plan de sondage.
Algorithme de tirage d’un SASSR de taille n parmi N
- Pour chaque \(k \in \mathcal,~ a_k \sim \mathcal{U}([0;1])\)
- Trier selon l’ordre croissant (ou décroissant) \(\{a_k\}\)
- Extraire les \(n\) premiers individus \(\to\) il s’agit d’un échantillon tiré selon un SASSR de taille \(n\) parmi N.
Plan poissonien
La plan poissonien est un plan de sondage prenant comme paramètres un vecteur \(\mathbb{p} = (\mathbb{p}_1, ..., \mathbb {p}_N) \in [0;1]^N \to {}\) il s’agira de la probabilité d’inclusion d’ordre 1.
\(S\) suit un plan poissonien (ou de Poisson) si :
- si pour tout sous-ensemble \(s\) de \(\mathcal{U}\) alors \(\displaystyle \mathbb{P}(S = s) = \prod_{k \in s} p_k \prod_{k \notin s} (1- p_k)\).
Le tirage poissonien consiste à tirer de manière (mutuellement) indépendante les individus. Chaque individu \(p_k\) a une probabilité \(p_k\) d’être tiré.
Ce plan est utilisé comme hypothèse pour décrire les mécanismes de non-réponse de type missing at random.
Probabilité d’inclusion d’ordre 1 et 2
Un plan de sondage \(p\) est donc défini par l’application \(s \to \mathbb{P}(S = s)\) où \(S\) est un échantillon aléatoire tiré sous \(p\).
Néanmoins, pour inférer sur les totaux (cadre de ce cours), il est suffisant de connaître les probabilités d’inclusion des individus.
Définition 6 (Indicatrice d’appartenance à l’échantillon)
- Pour tout individu \(k \in \mathcal{U}\) et pour tout échantillon \(S \subset \mathcal{U}\), l’indicatrice d’appartenance à l’échantillon \(S\) de l’individu \(k\) notée \(I_k(S)\) est la variable aléatoire \(I_k(S) = 1\) lorsque \(k \in S\) et \(I_k(S) = 0\) sinon.
- En pratique, il s’agit de marquer les individus tirés dans un échantillon.
- Souvent, on omet la dépendance à l’échantillon et on note plutôt \(I_k\).
Astuce (parfois utile) : \(\sum_{k \in S} a_k = \sum_{k \in \mathcal{U}} a_k I_k(S)\).
Probabilités d’inclusion
Définition 7 (Probabilités d’inclusion)
- La probabilité d’inclusion d’ordre 1 d’un individu \(k\) est la probabilité qu’un individu \(k\) appartienne à l’échantillon.
- Plus formellement, \(\pi_k = \mathbb{E}(I_k(S)) = \mathbb{P}(k \in S)\) où \(I_k(S) = 1\) si l’individu \(k \in S\) et 0 sinon.
- La probabilité d’inclusion d’ordre 2 de deux individus \(k\) et \(l\) est la probabilité que deux individus \(k\) et \(l\) appartienne (simultanément) à l’échantillon.
- Plus formellemment, : \(\pi_{kl} = \mathbb{E}(I_k(S) I_l(S)) = \mathbb{P}(\{k \in S\} \cap \{l \in S\} )\)
Il est possible de généraliser ces définitions aux probabilités d’inclusion d’ordre \(k\) avec \(k>2\).
On note pour tout \((k,l) \in \mathcal{U}^2\), la covariance des indicatrices d’apaprtenance \(\Delta_{kl} = \pi_{kl} - \pi_k \pi_l\) .
Lien entre plan de sondage et probabilités d’inclusion
À partir d’un plan de sondage \(p\), il est possible de calculer les probabilités d’inclusion d’ordre 1 et 2 associées à ce plan \(p\).
En effet, pour tout individu \(k \in \mathcal{U}\), \(\displaystyle \pi_k = \mathbb{P}(\underbrace{k \in S}_{\text{k appartient à l'échantillon tiré avec le plan de sondage}}) = \sum_{s \subset \mathcal{U} | k \in s } \mathbb{P}(S = s) = \sum_{s \subset \mathcal{U} | k \in s } p(s)\)
- La probabilité d’inclusion d’ordre \(1\) d’un individu \(k\) est la somme des probabilités des échantillons contenant l’individu \(k\).
Exemple
Soit la population \(\mathcal{U} = \{1,2,3,4\}\) et le plan de sondage \(p\) tel que :
\(p(\{ \emptyset \}) = 0 \\ p(\{ 1, 2, 3, 4 \}) = 0\)
\(p(\{ 1\}) = 0.07 \\ p(\{ 2 \}) = 0.03 \\ p(\{ 3 \}) = 0.08 \\ p(\{ 4 \}) = 0.02 \\\)
\(p(\{ 1,2\}) = 0.05 \\ p(\{ 1,3 \}) = 0.05 \\ p(\{ 1,4 \}) = 0.05 \\ p(\{ 2,3 \}) = 0.05 \\ p(\{ 3,4 \}) = 0.05 \\ p(\{ 2,4 \}) = 0.05\)
\(p(\{ 1,2,3\}) = 0.2 \\ p(\{ 2,3,4 \}) = 0.1 \\ p(\{ 1,3,4 \}) = 0.1 \\ p(\{ 1,2,4 \}) = 0.1\)
- \(p\) est bien un plan de sondage (mesure de probabilité sur \(\mathcal{P}(\{1,2,3,4\})\)).
- Calcul de \(\pi_1\) :
- \(\pi_1 = \underbrace{0.07}_{p(\{1\})} + \underbrace{0.05}_{p(\{1,2\})} + \underbrace{0.05}_{p(\{1,3\})} + \underbrace{0.05}_{p(\{1,4\})} + \underbrace{0.2}_{p(\{1,2,3\})} + \underbrace{0.1}_{p(\{1,3,4\})} + \underbrace{0.1}_{p(\{1,2,4\})} = 0.62\)
Lien entre plan de sondage et probabilités d’inclusion (2)
À partir d’un plan de sondage \(p\), il est possible de calculer les probabilités d’inclusion d’ordre 1 et 2 associées à ce plan \(p\).
En effet, pour tout individu \((k,l) \in \mathcal{U}^2\) avec \(k \neq l\), \(\displaystyle \pi_{kl} = \mathbb{P}(\underbrace{ \{ k \in S \} \cap \{ l \in S \}}_{\text{k et l appartiennent à l'échantillon tiré avec le plan de sondage}}) = \sum_{s \subset \mathcal{U} | k \in s \text{ et } l \in s} \mathbb{P}(S = s) = \sum_{s \subset \mathcal{U} | k \in s \text{ et } l \in s} p(s)\)
- La probabilité d’inclusion d’ordre \(1\) d’un individu \(k\) est la somme des probabilités des échantillons contenant l’individu \(k\).
Exemple
Soit la population \(\mathcal{U} = \{1,2,3,4\}\) et le plan de sondage \(p\) tel que :
\(p(\{ \emptyset \}) = 0 \\ p(\{ 1, 2, 3, 4 \}) = 0\)
\(p(\{ 1\}) = 0.07 \\ p(\{ 2 \}) = 0.03 \\ p(\{ 3 \}) = 0.08 \\ p(\{ 4 \}) = 0.02 \\\)
\(p(\{ 1,2\}) = 0.05 \\ p(\{ 1,3 \}) = 0.05 \\ p(\{ 1,4 \}) = 0.05 \\ p(\{ 2,3 \}) = 0.05 \\ p(\{ 3,4 \}) = 0.05 \\ p(\{ 2,4 \}) = 0.05\)
\(p(\{ 1,2,3\}) = 0.2 \\ p(\{ 2,3,4 \}) = 0.1 \\ p(\{ 1,3,4 \}) = 0.1 \\ p(\{ 1,2,4 \}) = 0.1\)
\(p\) est bien un plan de sondage (mesure de probabilité sur \(\mathcal{P}(\{1,2,3,4\})\)).
Calcul de \(\pi_{13}\) :
- \(\pi_{13} = \underbrace{0.05}_{p(\{1,3\})} + \underbrace{0.2}_{p(\{1,2,3\})} + \underbrace{0.1}_{p(\{1,3,4\})} + \underbrace{0}_{p(\{1,2,3,4\})} = 0.26\)
Remarque :
- pour tout \((k,l) \in \mathcal{U}^2\), \(\pi_{kl} = \pi_{lk}\).
- pour tout \(k \in \mathcal{U}\), \(\pi_{kk} = \mathbb{P}(\underbrace{\{k \in S\} \cap \{k \in S\}}_{= \{k \in S\}}) = \pi_k\)
Quelques types de plan de sondages
Il existe des plans de sondage avec des propriétés particulières :
Définition 8 (Plan de sondage simple) Un plan de sondage est simple si toutes les sous-ensembles de \(\mathcal{U}\) de même taille ont la même probabilité d’être tirée.
Définition 9 (Plan de sondage de taille fixe) Un plan de sondage est de taille fixe \(n\) si la probabilité de tirer un échantillon de taille différente de \(n\) est nulle. - Particulièrement utile pour contrôler le coût d’une enquête.
Définition 10 (Condition de Sen-Yates-Grundy) Un plan de sondage répond à la condition de Sen-Yates-Grundy si pour tout \((k,l)\) avec \(k \neq l\) alors \(\Delta_{kl} = \pi_{kl} - \pi_k \pi_l < 0\).
Exemple : Le plan aléatoire simple sans remise est simple, sans remise et répond à la condition de Sen-Yates-Grundy.
Rappel de statistique inférentielle
Estimateur, biais et variance
Le statisticien aimerait connaître une fonction d’intérêt \(\theta := \theta(\{\textbf{y}_k \}_{k \in \mathcal{U}})\) mais … cette quantité n’est pas évaluable dans la mesure où la variable d’intérêt n’est connue que pour les éléments de l’échantillon \(s\) \(\to\)
Il doit utiliser l’information disponible à partir de l’échantillon \(s\) pour essayer d’estimer \(\theta\).
Analogie de la recette de cuisine :
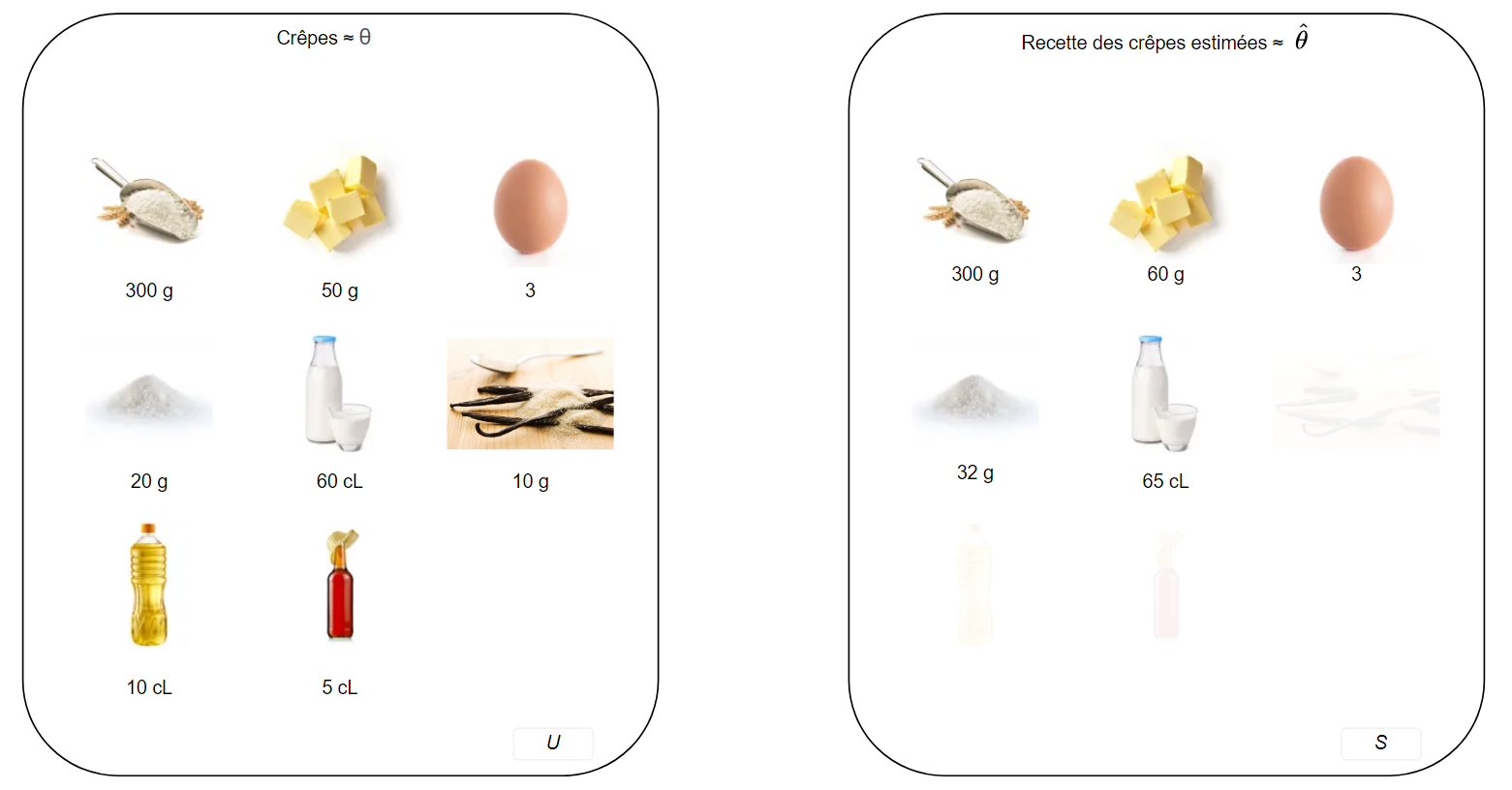
Analogie de la recette de cuisine :
- Les ingrédients \(\to\) la population \(\mathcal{U}\)
- Les crêpes \(\to\) la fonction d’intérêt \(\theta\) (il s’agit d’une fonction des ingrédients)
- Dans l’exemple de droite, seule une partie des ingrédients est disponible
- La recette basée sur les ingrédients disponibles \(\to\) estimateur \(\hat \theta\).
- Des crêpes avec la recette dégradée \(\to\) estimation. 🥞
Intuitivement, la manière avec laquelle on va tenter d’estimer \(\theta\) s’appelle un estimateur.
Définition 11 (Estimateur (design-based) - cas simplifié sans variables auxiliaires) Un estimateur \(\hat\theta\) de \(\theta := \theta(\{\textbf{y}_k \}_{k \in \mathcal{U}})\) est une fonction (mesurable) de la variable d’intérêt observé sur l’échantillon \(S\).
Une estimation associée à un estimateur \(\hat\theta\) est une réalisation de cet estimateur.
- Parmi l’ensemble des estimateurs, nous nous interesserons exclusivement aux estimateurs linéaires.
Définition 12 (Estimateur linéaire - cas simplifié sans variables auxiliaires) Un estimateur \(\hat\theta\) de \(\theta := \theta(\{\textbf{y}_k \}_{k \in \mathcal{U}})\) est dit linéaire s’il s’écrit sous la forme \(\displaystyle \sum_{k \in S} w_k y_k\).
Les coefficients \(w_k\) sont appelés poids de l’individu \(k\) associé à l’estimateur \(\hat\theta\).
Une interprétation des poids de sondage : l’individu \(k\) de l’échantillon représente \(w_k\) de la population \(\mathcal{U}\).
- Exemples
- Si \(\displaystyle \theta_1(\{\textbf{y}_k \}_{k \in \mathcal{U}}) = \frac{1}{N} \sum_{k \in \mathcal{U}} \textbf{y}_k\) on peut prendre comme estimateur \(\displaystyle \hat \theta_1(\{\textbf{y}_k \}_{k \in S}) = \frac{1}{n} \sum_{k \in S} \textbf{y}_k\) :
- La moyenne sur la population est estimée par la moyenne sur l’échantillon.
- Si \(\displaystyle \theta_2(\{\textbf{y}_k \}_{k \in \mathcal{U}}) = \sum_{k \in \mathcal{U}} \textbf{y}_k\) on peut prendre comme estimateur \(\displaystyle \hat \theta_2(\{\textbf{y}_k \}_{k \in S}) = \sum_{k \in S} \textbf{y}_k\) MAIS …
- Le total sur la population est estimé par le total sur l’échantillon.
- Si \(\displaystyle \theta_1(\{\textbf{y}_k \}_{k \in \mathcal{U}}) = \frac{1}{N} \sum_{k \in \mathcal{U}} \textbf{y}_k\) on peut prendre comme estimateur \(\displaystyle \hat \theta_1(\{\textbf{y}_k \}_{k \in S}) = \frac{1}{n} \sum_{k \in S} \textbf{y}_k\) :
Application
- Dans notre exemple, on souhaitait le coût total en euros pour le transport en commun pour l’ensemble des individus de \(\mathcal{U}\) soit \(\displaystyle t_\textbf{y} = \sum_{k = 1}^{10} \textbf{y}_k\).
- En utilisant l’exemple précédent, il est possible d’utiliser \(\hat \theta_2\) comme estimateur.
- L’estimation induit par l’estimateur \(\hat \theta_2\) donne \(174 €\).
- Est-ce un bon estimateur d’après vous ?
- Qu’est qu’un bon estimateur ?
- Critère pour évaluer ces estimateurs ?
Définition 13 (Biais d’un estimation) Le biais d’un estimateur \(\hat \theta\) d’une fonction d’intérêt \(\theta\) est donné par \(\mathbb{B}(\hat \theta; \theta) = \mathbb{E}(\hat \theta) - \theta\).
Un estimateur dont le biais est nul est dit sans biais.
- L’estimateur \(\hat \theta_2\) est biaisé pour \(\theta_2\). En effet, \(\displaystyle \mathbb{E}(\hat \theta_2 - \theta_2) = \sum_{k \in \mathcal{U}} \textbf{y}_k (\pi_k - 1)\).

- Autre moyen de comparer des estimateurs basé sur la variabilité ?
- Est-ce que si j’avais tiré un autre échantillon, mon estimateur aurait été très différent ?
Définition 14 (Variance) La variance d’un estimateur \(\hat \theta\) d’une fonction d’intérêt \(\theta\) est donné par \(\mathbb{V}(\hat \theta) = \mathbb{E}(\left(\hat \theta - \mathbb{E}(\hat \theta) \right)^2)\).
La variance permet de quantifier la variabilité d’un estimateur.
Il est possible de combiner le biais et la variance en un critère : l’erreur quadratique moyenne
Définition 15 (Erreur quadratique moyenne) L’erreur quadratique moyenne d’un estimateur \(\hat \theta\) d’une fonction d’intérêt \(\theta\) est donné par \(\text{MSE}(\hat \theta) = \mathbb{E}(\left(\hat \theta - \theta \right)^2)\).
La MSE quantifie la distance entre l’estimateur et la fonction d’intérêt. Cette mesure permet de quantifier la qualité d’un estimateur.
Propriété : décomposition de la MSE
Pour tout estimateur \(\hat \theta\) de \(\theta\),
\[\text{MSE}(\hat \theta) = \mathbb{B}(\hat \theta;\theta)^2 + \mathbb{V}(\hat \theta)\]
Démonstration : décomposition de la MSE
\[\text{MSE}(\hat \theta) = \mathbb{E}\left(\left(\hat \theta - \theta \right)^2\right)\] \[= \mathbb{E}\left(\left(\hat \theta - \mathbb{E}(\hat \theta) + \mathbb{E}(\hat \theta) - \theta \right)^2\right)\] \[= \mathbb{E}\left(\left(\hat \theta - \mathbb{E}(\hat \theta) \right)^2 + 2 \left( \hat \theta - \mathbb{E}(\hat \theta) \right) \left( \mathbb{E}(\hat \theta) - \theta \right) + \left( \mathbb{E}(\hat \theta) - \theta \right)^2\right)\] \[= \mathbb{E}\left(\left(\hat \theta - \mathbb{E}(\hat \theta) \right)^2 \right) + \mathbb{E}\left( 2 \left( \hat \theta - \mathbb{E}(\hat \theta) \right) \left( \mathbb{E}(\hat \theta) - \theta \right) \right) + \mathbb{E}\left(\left( \mathbb{E}(\hat \theta) - \theta \right)^2\right)\] \[= \mathbb{E}\left(\left(\hat \theta - \mathbb{E}(\hat \theta) \right)^2 \right) + 2 \left( \mathbb{E}(\hat \theta) - \theta \right) \mathbb{E}\left( \hat \theta - \mathbb{E}(\hat \theta) \right) + \left( \mathbb{E}(\hat \theta) - \theta \right)^2\] \[= \mathbb{E}\left(\left(\hat \theta - \mathbb{E}(\hat \theta) \right)^2 \right) + 2 \left( \mathbb{E}(\hat \theta) - \theta \right) \left( \mathbb{E}(\hat \theta) - \mathbb{E}\left(\mathbb{E}(\hat \theta)\right) \right) + \left( \mathbb{E}(\hat \theta) - \theta \right)^2\] \[= \mathbb{E}\left(\left(\hat \theta - \mathbb{E}(\hat \theta) \right)^2 \right) + 2 \left( \mathbb{E}(\hat \theta) - \theta \right) \left( \mathbb{E}(\hat \theta) - \mathbb{E}\left(\hat \theta\right) \right) + \left( \mathbb{E}(\hat \theta) - \theta \right)^2\] \[= \mathbb{E}\left(\left(\hat \theta - \mathbb{E}(\hat \theta) \right)^2 \right) + \left( \mathbb{E}(\hat \theta) - \theta \right)^2\] \[= \mathbb{V}(\hat \theta) + \mathbb{B}(\hat \theta;\theta)^2\]
Est-ce que le biais est l’alpha et l’oméga du statisticien ?
La MSE permet de quantifier la qualité d’un estimateur : il s’agit de la distance (moyenne) entre l’estimateur et le paramètre à estimer.
Intuitivement, la recherche d’un estimateur semble être une condition nécessaire en inférence.
Néanmoins, il est parfois préférable d’autoriser un peu de biais afin de réduire drastiquement la variance (donc baisse de la MSE.)
Définition : coefficient de variation
Le coefficient de variation d’un estimateur \(\text{CV}(\hat \theta)\) est le rapport entre son écart type et son espérance.
Autrement dit : \(\displaystyle \text{CV}(\hat \theta) : \frac{\mathbb{V}^{\frac{1}{2}}(\hat \theta)}{\mathbb{E}(\hat \theta)}\)
Ce coefficient n’a pas d’unité : permet les comparaisons sur des estimateurs liés à des grandeurs différentes.

Estimateur de Narain-Horvitz-Thompson
Estimation d’un total par l’estimateur de Narain-Horvitz-Thompson
Nous considérons :
- une population \(\mathcal{U}\) de taille \(N\)
- un échantillon \(s\) tiré selon un plan de sondage \(\mathcal{p}\).
- \(\{\pi_k\}_{k \in \mathcal{U}}\) et \(\{\pi_{kl}\}_{(k,l) \in \mathcal{U}^2}\) désignent (resp) les probabilités d’inclusion d’ordre 1 et d’ordre 2.
- une variable d’intérêt \(\textbf{y} = (y_1, ..., y_N)\) à valeur réelle (sans perte de généralité).
- cette variable n’est observable que pour les individus de l’échantillon.
But : estimer le total \(t_\textbf{y}\) de la variable d’intérêt \(\textbf{y}\) sur l’ensemble de la population avec \(\displaystyle t_\textbf{y} = \sum_{k \in \mathcal{U}} \textbf{y}_k\).
Estimation d’un total par l’estimateur de Narain-Horvitz-Thompson
Définition 16 (Estimateur de (Narain)-Horvitz-Thompson ou \(\pi-\)estimateur) L’estimateur \(\hat t_{y,\text{HT}}\) du total \(t_y\) défini par \(\displaystyle \hat t_{y,\text{HT}} := \sum_{k \in S} \frac{y_k}{\pi_k}\) est l’estimateur d’Horvitz-Thompson du total \(t_y\).
Théorème 1 (Biais de \(\hat t_{y,\text{HT}}\)) Si pour tout individu \(k \in \mathcal{U} ~ \pi_k > 0\), alors l’estimateur de Horvitz-Thompson est sans biais. Preuve)
Ce cours se basera majoritairement sur l’estimateur d’Horvitz-Thompson.
- Intuition : les individus de l’échantillon sont repondérés de telle manière à représenter les individus non tirés.
- L’individu \(k\) représente \(w_k = \frac{1}{\pi_k}\) individus.
- Remarque : \(\displaystyle \hat t_{y,\text{HT}} := \sum_{k \in S} \frac{y_k}{\pi_k} = \sum_{k \in \mathcal{U}} \frac{y_k}{\pi_k} I_k\)
- Cet estimateur est linéaire avec des poids \(w_k = \frac{1}{\pi_k}\) \(\to\) les poids associés à l’individu ne dépendent pas de l’échantillon.
Exemple d’application
Nous avons tenté d’estimer le coût total en transport sur notre population.
- \(\displaystyle \theta_2(\{\textbf{y}_k \}_{k \in \mathcal{U}}) = \sum_{k \in \mathcal{U}} \textbf{y}_k\) est biaisé…
Supposons que l’échantillon \(s = \{1,5,7,10\}\) ait été tiré en utilisant un plan aléatoire simple sans remise de taille \(n\) = 4.
\(\to\) Pour chaque \(k \in \mathcal{U} = \{1, ... 10\}\), \(\pi_k = \frac{4}{10}\).
L’estimateur de Horvitz-Thompson donne \(\frac{y_1}{\pi_1} + \frac{y_5}{\pi_5} + \frac{y_7}{\pi_7} + \frac{y_{10}}{\pi_{10}}\).
Une estimation associée est \((84 + 30 + 30 + 30) \times \frac{10}{4} = 435 €\).
Estimation par subtitution
- À partir d’un estimateur du total, il est possible de proposer des estimateurs pour une série de fonctions d’intérêt :
- Par exemple, la moyenne arithmétique : \(\displaystyle \frac{1}{N} \sum_{k \in \mathcal{U}} y_k\) est estimable par \(\displaystyle \frac{1}{N} \hat t_{y,\text{HT}}\).
- Cet estimateur est sans biais si pour tout individu \(\displaystyle k \in \mathcal{U}\) \(\pi_k > 0\).
- D’une manière générale, une approche plug-in (ou par substitution) est mobilisable :
- La fonction d’intérêt de la forme \(\displaystyle f(t_y)\) est estimable par \(\displaystyle f(\hat t_{y,\text{HT}})\)
- Problème : sauf pour certaines fonctions, le biais et la variance de l’estimateur \(\displaystyle f(t_y)\) ne sont pas directement calculables.
- Cas général : cet estimateur n’est pas sans biais.
- Nous verrons dans le prochain cours qu’il est possible de faire des approximations afin de calculer la variance (linéarisation).
Ce que nous avons vu aujourd’hui
- Population et échantillon.
- Variables : variables d’intérêt, variables auxiliaires et fonction d’intérêt.
- Plan de sondage.
- Estimateur d’Horvitz-Thompson pour le total.
- Biais de cet estimateur.
- Estimateur dérivé.
Merci de votre attention
Aparté 1 : Est-ce que les variables d’intérêt et les variables auxiliaires sont aléatoires ?
Dans ce cours, nous considérons que les variables d’intérêt et les variables auxiliaires sont déterministes.
La seule source d’aléa sera issue du tirage de l’échantillon : il s’agit de l’approche design-based.
D’autres approches permettant de considérer simultannément l’aléa de tirage (modèle de superpopulation, …).
Défaut de couverture et hors champ
L’échantillon est un sous-ensemble de la population \(\to\) suppose l’existence d’une base avec tous les individus de la population \(\to\) il s’agit de la base de sondage.
En pratique : (très) souvent difficile d’avoir une base de sondage parfaite.
Exemple (hors champ) : enquête Elipa 1 (version 2010-2013).
- Enquête visant à “appréhender au plus près le parcours d’intégration des migrants auxquels vient d’être délivré un premier titre de séjour depuis leur arrivée en France.” (Source : CNIS)
- La population est constitué des personnes ayant un premier titre de séjour d’au moins un an ET signataires du CAI.
- L’échantillon est tiré dans la liste des signataires du CAI.
Exemple (défaut de couverture) : enquête CAMME.
- Enquête visant à connaître l’opinion des ménages vis-à-vis la conjoncture économique. Elle vise à obtenir également des informations sur leur situation financière personnelle et leurs intentions d’épargne et de consommation.
- La population est l’ensemble des ménages vivant dans un logement ordinaire.
- L’échantillon est tiré en utilisant l’annuaire téléphonique et les coordonnées téléphoniques des bases fiscales.

Différence entre \(s\) et \(S\)
Comme en probabilité, il convient de distinguer :
- l’objet porteur d’aléa : l’échantillon aléatoire désigné par \(S\). Formellement \(S\) est une application d’un espace probabilisable dans \((\mathcal{P}(U), \mathcal(\mathcal{P}(U)))\)
- la réalisation de l’aléa : l’échantillon \(s\). Il s’agit d’un élement de \(\mathcal{P}(U)\).
Une analogie est possible avec les variables aléatoires.
La variable aléatoire \(X \sim \text{Ber}(p)\) désigne le phénomène aléatoire alors que \(x = 1\) désigne une réalisation de cet aléa.
Exemple : SASSR(n)
Pour un plan SASSR(n) alors :
- pour tout \(k \in \mathcal{U}, ~\pi_k = \frac{N}{n}\)
- pour tout \((k,l) \in \mathcal{U}^2, ~\pi_{kl} = \frac{N(N-1)}{n(n-1)}\) si \(k \neq l\) et \(\pi_{kl} = \pi_{k}\) sinon.
Exemple : plan poissonien
Pour un plan poissonien de paramètre \(p = (p_1, ..., p_N)\) alors :
- pour tout \(k \in \mathcal{U}, ~\pi_k = p_k\)
- pour tout \((k,l) \in \mathcal{U}^2, ~\pi_{kl} = p_k p_l\) si \(k \neq l\) et \(\pi_{kl} = p_k\) sinon.
Preuve de l’absence de biais de l’estimateur d’Horvitz-Thompson.
Considérons un plan de sondage \(p\) sur une population \(\mathcal{U}\) tel que pour tout \(k \in \mathcal{U}, ~ \pi_k > 0\).
L’estimateur d’Horvitz-Thompson est donné par \(\displaystyle \hat t_{y,\text{HT}} := \sum_{k \in S} \frac{y_k}{\pi_k}\).
\(\mathbb{E}(\hat t_{y,\text{HT}}) = \mathbb{E}(\sum_{k \in \mathcal{S}} \frac{y_k}{\pi_k}) = \mathbb{E}(\sum_{k \in \mathcal{U}} \frac{y_k}{\pi_k} I_k) = \sum_{k \in \mathcal{U}} \frac{y_k}{\pi_k} \mathbb{E}(I_k) = \sum_{k \in \mathcal{U}} y_k\)